ShadowGuard Exposed: Inside the eBPF Rootkit That Made 70 Organizations Blind to Their Own Kernel
On February 5, 2026, Unit 42 published the details of TGR-STA-1030, an Asia-nexus group Mandiant tracks in parallel as UNC6619. Buried in the campaign write-up was a single SHA-256 hash for a Linux implant called ShadowGuard, and that implant is the reason this campaign matters more than the average state-aligned espionage report. It does not live in /proc/modules. It does not taint the kernel. It runs inside the same BPF virtual machine your EDR uses to watch for threats, and it edits reality before your tools ever read it.
If you administer Linux infrastructure and your entire rootkit-detection strategy is rkhunter, chkrootkit, and lsmod, you are already blind to this class of implant. Let me show you exactly why, down to the struct fields being rewritten in userspace memory.
What Unit 42 actually confirmed (and what got inflated)
Before the mechanics, get the facts straight, because the early secondhand coverage overreached in a few places and I do not want you repeating claims you cannot defend in an incident review.
Here is what is confirmed:
| Item | Confirmed detail |
|---|---|
| Disclosure | Unit 42, February 5, 2026 |
| Group | TGR-STA-1030 (Unit 42), UNC6619 (Mandiant). “TGR-STA” is a placeholder prefix for temporary state-aligned activity pending firmer attribution. |
| Attribution | High confidence the group operates out of Asia, pursuing geopolitical and economic objectives, not money. Activity patterns consistent with GMT+8. |
| Scale | At least 70 organizations compromised across 37 countries. A mix of government and critical infrastructure, not government alone. |
| Recon | Between November and December 2025, active reconnaissance against government infrastructure tied to 155 countries. |
| Longevity | Infrastructure dating to January 2024. Active at least two years. |
| ShadowGuard hash | 7808B1E01EA790548B472026AC783C73A033BB90BBE548BF3006ABFBCB48C52D |
| Vuln posture | No zero-days. Aggressive N-day weaponization: SAP Solution Manager, Microsoft Exchange, D-Link, Windows. At least 15 CVEs across the campaign. |
And here is what got embellished in the retellings. The “37-country government compromise” framing conflates the 155-country reconnaissance sweep with the 37 countries where compromise was confirmed, and folds critical-infrastructure victims into a “government-only” number. Small distinction, big deal when you are briefing leadership.
The more important correction is technical. You will see claims that ShadowGuard “hooks sys_read and sys_write.” Unit 42 did not confirm those specific hooks. What Unit 42 confirmed is syscall interception for process and file concealment, which is the classic getdents/getdents64 behavior. The sys_read/sys_write audit-suppression path is a real and well-documented eBPF rootkit technique, but treat it as the class mechanic these implants generally use, not a verified ShadowGuard-specific claim. When I walk through audit suppression later, that is the framing.
The intrusion chain, top to bottom
ShadowGuard is the last thing that lands on a box, not the first. Understanding the full path matters because most defenders will catch this campaign at an earlier, noisier stage long before the rootkit ever gets a chance to blind them.
Stage one: the Diaoyu loader
“Diaoyu” translates to “fishing,” which is exactly what it is. Delivery is tailored phishing referencing internal ministry reorganizations, with links to malicious archives hosted on Mega.nz. One confirmed sample masqueraded as an Estonian border-police restructuring document: Politsei- ja Piirivalveameti organisatsiooni struktuuri muudatused.exe, carrying a Microsoft Word icon and signed with a spoofed “Zoom Video Communications, Inc.” certificate. It is a C++ binary built with Visual Studio 2019, PE compile timestamp February 13, 2025, internal name DiaoYu.exe.
What makes Diaoyu worth studying is its guardrails. It refuses to detonate in an analyst’s sandbox using two cheap but effective checks:
- Screen resolution gate. Horizontal resolution must be at least 1440 pixels. Automated sandboxes routinely run at smaller virtual resolutions.
- Companion-file gate. It looks for
pic1.pngin its execution directory. No file, graceful exit before any malicious behavior fires. This is a delivery-package check: the real phishing archive ships both files together, so a lone binary submitted to VirusTotal does nothing interesting.
# Diaoyu-style guardrail logic (educational reconstruction)
import ctypes, os
width = ctypes.windll.user32.GetSystemMetrics(0) # SM_CXSCREEN
if width < 1440:
exit(0) # too small: likely a sandbox
if not os.path.exists("pic1.png"): # companion file must be present
exit(0) # unpacked in isolation: bail
# only now does it enumerate AV and fetch a payload
After the gates, it enumerates running security products, checking for Kaspersky (avp.exe), SentinelOne (SentinelUI.exe), Bitdefender (EPSecurityService.exe), Norton (NortonSecurity.exe), and Avira. If the host looks safe, Diaoyu resolves its network APIs dynamically through urlmon.dll (community Sigma flags this as T1027.007, dynamic API resolution) and pulls down its next stage: typically a Cobalt Strike beacon as the early foothold, then a pivot to VShell, a Go-based C2 framework, with Havoc, Sliver, and SparkRat showing up occasionally.
The detection anchor here is Sysmon. Event ID 7 (ImageLoaded) catches the urlmon.dll load in a process that has no business touching it, and Event ID 11 (FileCreate) catches the beacon dropping into user-writable paths.
Stage two: web shell pivot and tunneling
On external and internal web servers, the group plants Behinder, Neo-reGeorg, and Godzilla web shells. The Godzilla variants are obfuscated with the Tas9er project, which renames functions and strings to look like “Baidu” tokens. For traffic movement they lean on GOST, FRPS, and IOX to tunnel C2 out of the network.
The infrastructure is deliberately layered. Victim-facing C2 sits on reputable VPS providers in the US, UK, and Singapore. Relays run over SSH or RDP. Anonymization goes through residential proxies or Tor. Occasionally the upstream leaks AS9808, which is China Mobile. That leak, plus the GMT+8 working hours and a recurring “JackMa” operator handle, is the backbone of the Asia-nexus attribution.
Once the group has root on a Linux target through a web shell or an N-day, ShadowGuard goes down.
eBPF in ninety seconds, for people who defend systems
To understand why this rootkit is dangerous, you need to internalize what eBPF actually is, because “extended Berkeley Packet Filter” undersells it badly. eBPF is a way to run sandboxed programs inside the Linux kernel without writing a kernel module. You compile bytecode, hand it to the kernel through the bpf() syscall, and the kernel’s verifier statically proves the program cannot loop forever, cannot read out of bounds, and cannot crash the box. If it passes, a JIT compiler turns it into native machine code that runs at kernel speed, attached to a hook point of your choosing.
That verifier is the whole story. It is why observability vendors, EDRs, and CNCF projects fell in love with eBPF: you get kernel-level visibility with kernel-level performance and near-zero panic risk. And it is exactly why attackers love it too. A rootkit that passes the verifier gets the same trust the kernel extends to Falco or Cilium.
The program types that matter for rootkits:
| Program type | Attach point | Rootkit use |
|---|---|---|
| Tracepoint | sys_enter_getdents64 / sys_exit_getdents64 | Filter directory entries to hide files and PIDs |
| Kprobe / kretprobe | Any kernel function entry/return | Intercept and rewrite return values |
| fentry / fexit | Function entry/exit via BPF trampoline (5.5+) | Lower-overhead hooking, blends with legit telemetry |
| XDP / TC | Driver ingress / egress | Magic-packet C2 triggers below the network stack |
| LSM BPF | Linux Security Module hooks | Policy and audit suppression |
The connective tissue is BPF maps, shared key/value stores readable from both kernel and userspace. A rootkit uses a map as its config: the list of PIDs to hide, the allow-list of processes to leave visible, the magic byte sequence for a network trigger. ShadowGuard’s confirmed limit of 32 simultaneously hidden processes is almost certainly a 32-entry BPF_MAP_TYPE_HASH.
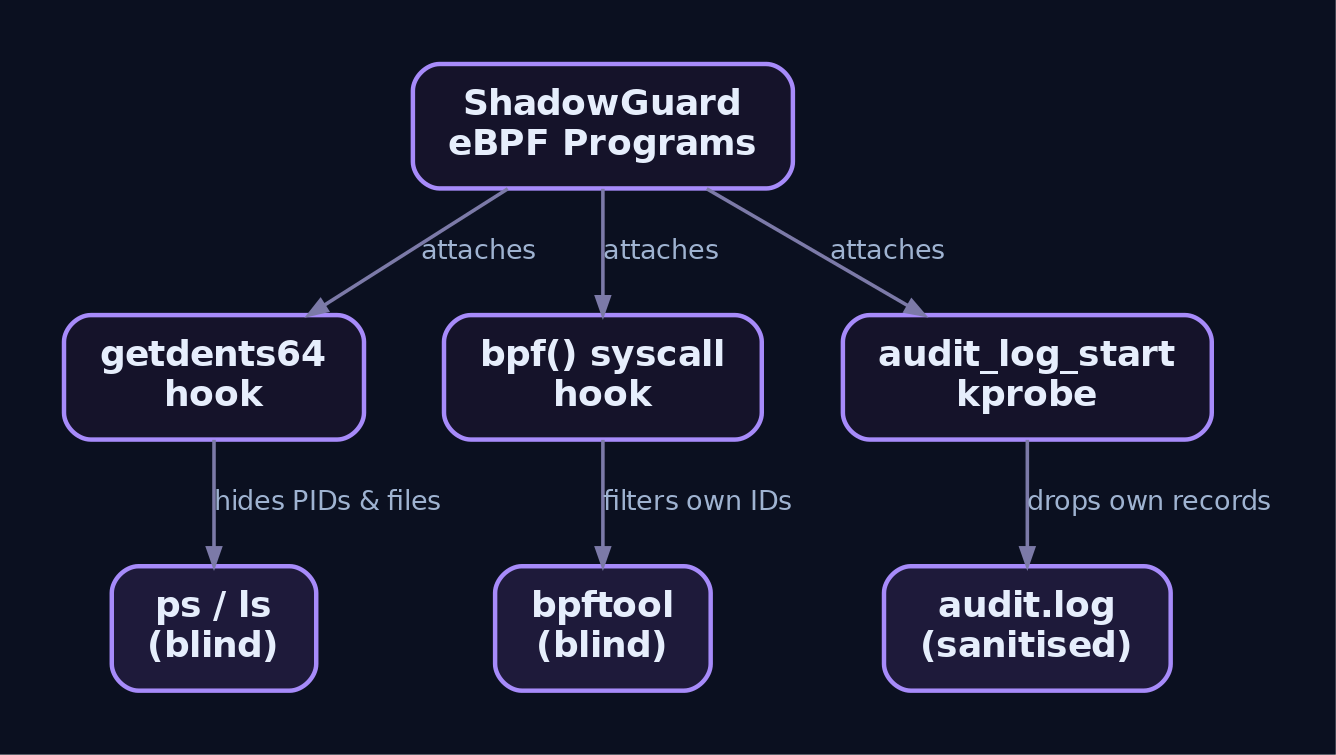
How the process hiding actually works
This is the core mechanic, and once you see it, ShadowGuard’s confirmed behavior (hiding up to 32 PIDs from ps aux, hiding files named swsecret) stops being magic.
When you run ps, ls, or top, userspace ultimately calls getdents64 to read directory entries out of /proc or a filesystem. The kernel fills a userspace buffer with a packed array of linux_dirent64 structs, one per entry:
struct linux_dirent64 {
u64 d_ino; // inode number
s64 d_off; // offset to the next dirent
unsigned short d_reclen; // *** length of THIS entry: the skip pointer ***
unsigned char d_type;
char d_name[]; // null-terminated filename
};
The field that matters is d_reclen. Userspace does not walk this buffer with pointer arithmetic it controls. It reads an entry, then advances by that entry’s d_reclen to find the next one. d_reclen is a trust-me pointer. If you can lie about it, you can make readdir walk right over an entry as if it never existed.
The rootkit attaches a tracepoint to sys_exit_getdents64, which fires after the kernel has populated the userspace buffer but before control returns to ps. At that instant the malicious entry is sitting in memory, fully formed. The eBPF program then:
- Reads each entry’s
d_namewithbpf_probe_read_user. - Looks up the name (or the PID it represents) in its hidden-PID hash map.
- On a hit, it does not delete the entry. It rewrites the previous entry’s
d_reclento add the hidden entry’s length, so userspace leaps over the hidden record entirely.
// tracepoint/syscalls/sys_exit_getdents64 (educational, bad-bpf style)
//
// prev = last dirent we decided to KEEP
// cur = current dirent, matched against the hide map
//
// To hide `cur`, absorb its length into prev's skip pointer:
unsigned short new_reclen = prev_reclen + cur_reclen;
// Patch the userspace buffer in place. This is the tell.
bpf_probe_write_user(&prev_dirent->d_reclen,
&new_reclen,
sizeof(new_reclen));
That bpf_probe_write_user call is the single most important indicator in this entire class. Legitimate observability programs read kernel and userspace memory constantly. They almost never write to userspace memory. A BPF program calling bpf_probe_write_user is, in practice, either a rootkit or a research toy. Tetragon can alert on it directly.
Because /proc/1234 vanishes from the directory listing but the process is fully alive in the kernel’s task list, ps aux shows nothing while the process keeps running, keeps holding sockets, keeps beaconing. The 32-PID ceiling exists because iterating and patching entries inside a verifier-bounded program is not free, and the map that holds the targets is sized for it. The allow-list is the inverse: named processes the operators deliberately leave visible so a half-empty ps output does not itself become suspicious.
You can reproduce the entire mechanic safely in a lab with the open-source bad-bpf project (MIT-licensed, built for exactly this kind of education):
git clone https://github.com/pathtofile/bad-bpf && cd bad-bpf && make
# Hide the mock target PID from getdents64
sudo ./pidhide --pid-to-hide $(pgrep mock-gov-data)
ps aux | grep mock-gov-data # returns nothing
ls -d /proc/$(pgrep mock-gov-data) # kernel still has it
Same trick, same struct, applied to filenames instead of PIDs, is how ShadowGuard hides anything named swsecret. It is a string match against d_name in the tracepoint, and every file, directory, or dropped tool the operators name swsecret becomes invisible to ls, find, and every forensic tool that walks a directory through the syscall interface.

Audit suppression and the self-hiding problem
Hiding from ps is stage one. The reason eBPF rootkits are genuinely hard to catch is that they can also hide from the tools you would use to catch them, and from the logs that would record their activity.
Suppressing the audit trail
This is the class mechanic I flagged earlier, the one attributed to sys_read/sys_write in loose reporting but not confirmed for ShadowGuard specifically. It works like this. The audit daemon writes records to /var/log/audit/audit.log via the write() syscall. A rootkit hooks the write path, inspects the buffer with bpf_probe_read_user, and when it sees its own process names or the string swsecret, it short-circuits the write so the record never lands. A cleaner variant hooks audit_log_start() directly with a kprobe and drops the record before it is even formatted.
The result: ausearch shows a tidy, complete-looking audit log with the rootkit’s activity surgically excised, while /proc still contains the processes doing the work. The log looks healthy. That is the point.
Hiding from bpftool
Here is the recursion that makes this class nasty. Your natural response is bpftool prog list to enumerate loaded BPF programs. But bpftool enumerates by issuing bpf() syscalls, specifically BPF_PROG_GET_NEXT_ID and BPF_OBJ_GET_INFO_BY_ID. A rootkit that hooks the bpf() syscall filters those responses to omit its own program IDs. Run bpftool prog list and you get a clean list that does not include the thing filtering the list.
bpftool, ps, and netstat all make syscalls the rootkit already intercepts. You cannot trust a query when the thing you are querying about controls the answer.
The ground truth lives in prog_idr, the kernel’s internal IDR structure that tracks every loaded BPF program by ID. That structure is authoritative and lives below the syscall layer. Reading it requires bypassing syscalls entirely: a memory acquisition with LiME plus Volatility3 analysis, or a trusted eBPF monitor loaded before the rootkit ever ran. Load order is everything. Falco and Tetragon register their hooks at boot, before any attacker code executes, which is why they can still observe the bpf() call that loads the rootkit even though a post-hoc bpftool run comes up empty.
LKM rootkits vs eBPF rootkits: why the old playbook fails
If your mental model of a Linux rootkit is Diamorphine or an insmod‘d kernel module, throw it out for this threat. The two classes are not variations on a theme. They live on opposite sides of the kernel’s trust boundary.
| Dimension | LKM rootkit (Diamorphine) | eBPF rootkit (ShadowGuard) |
|---|---|---|
| Load mechanism | insmod / modprobe, visible in /proc/modules | bpf() syscall, absent from /proc/modules |
| Kernel taint | Sets TAINT_OOT_MODULE | No taint, passes the kernel’s own verifier |
| Secure Boot | Blocked by module signature enforcement | Can bypass Secure Boot restrictions entirely |
| Crash risk | High, a buggy module panics the box | Low, the verifier rejects unsafe code pre-JIT |
| Hook method | Overwrites syscall-table function pointers | Attaches to tracepoints/kprobes, no pointers touched |
| Portability | Tied to exact kernel version | CO-RE and verifier-checked JIT, far more portable |
rkhunter/chkrootkit | Partially detectable | Blind, these tools scan for LKM artifacts that do not exist here |
Read that Secure Boot row again. Organizations enable Secure Boot specifically to stop unsigned kernel code, and it works against modules. eBPF sidesteps the entire concern because the code path is the sanctioned bpf() interface, not module loading. A hardening control most teams consider a rootkit backstop does nothing here.

Detection and defense that survives self-concealment
The winning move against this class is not a better scanner run after the fact. It is telemetry that exists before the rootkit does, plus periodic ground-truth checks that bypass the syscall layer the rootkit controls.
Watch the loading event, not the loaded artifact
You cannot reliably enumerate a rootkit that hides from enumeration. You can catch the moment it loads, because a pre-installed monitor sees the bpf() syscall before the rootkit’s own hooks are live.
# Alert on every bpf() program-load, with the calling process
sudo bpftrace -e '
tracepoint:syscalls:sys_enter_bpf /args->cmd == 5/ {
printf("BPF_PROG_LOAD by pid=%d comm=%s uid=%d\n", pid, comm, uid);
}'
# cmd 5 = BPF_PROG_LOAD, cmd 0 = BPF_MAP_CREATE
Any BPF_PROG_LOAD from a process that is not your known observability stack is an incident until proven otherwise. Feed this into auditd for durable logging:
auditctl -a always,exit -F arch=b64 -S bpf -k ebpf_load
auditctl -a always,exit -F arch=b64 -S getdents64 -F uid!=0 -k suspicious_dir
Enumerate BPF state at acquisition time, first
The instant you touch a suspect host, before anything new can load, capture the BPF state:
bpftool prog list --json # look for unnamed programs, kprobe/tracepoint types on non-observability hosts
bpftool map list # unexpected BPF_MAP_TYPE_HASH maps are prime IOCs
ls -la /sys/fs/bpf/ # pinned objects a legitimate stack did not create
cat /sys/kernel/debug/tracing/enabled_functions | \
grep -E 'sys_getdents64|vfs_read|do_send_sig_info|audit_log_start'
Unexpected ftrace hooks on __x64_sys_getdents64, vfs_read, or audit_log_start are exactly the functions this class targets.
Cross-check reality against itself
The most reliable field detection is a discrepancy check. Watch process execution at a hook the rootkit did not capture, then compare against what ps admits exists:
# Ground truth: every exec the scheduler sees
bpftrace -e 'tracepoint:sched:sched_process_exec {
printf("exec pid=%d %s\n", pid, str(args->filename));
}'
# Diff the PIDs this reports against: ps -eo pid,comm
A PID that fires sched_process_exec but never appears in ps is being hidden. The rootkit filters getdents64, not the scheduler tracepoint, so the two views disagree, and the disagreement is your signal.
Deploy eBPF-native monitors, correctly ordered
| Tool | What it catches |
|---|---|
| Falco | Hooks registered at startup, before attacker load. Rule on bpf() from non-allowlisted processes. |
| Tetragon | Kernel execution tracing. Alerts on bpf_probe_write_user, which legit observability never does. |
| Tracee | Compares live syscall-table addresses against expected values to catch hooking. |
Load order is not optional. A monitor loaded after the rootkit is already inside its blind spot. Bake Falco or Tetragon into your golden image and start them at boot.
MITRE ATT&CK mapping
| Technique | ID | Where it shows up |
|---|---|---|
| Spearphishing Link | T1566.002 | Mega.nz-hosted archive |
| Dynamic API Resolution | T1027.007 | Diaoyu via urlmon.dll |
| Virtualization/Sandbox Evasion | T1497 | Resolution and pic1.png gates |
| Server Software Component: Web Shell | T1505.003 | Behinder, Neo-reGeorg, Godzilla |
| Protocol Tunneling | T1572 | GOST, FRPS, IOX |
| Rootkit | T1014 | ShadowGuard eBPF implant |
| Hide Artifacts | T1564 | getdents64 PID and swsecret file hiding |
| Impair Defenses: Indicator Blocking | T1562.006 | Audit log suppression |
| Exploitation of Remote Services | T1210 | 15+ N-day CVEs |

Key takeaways
- ShadowGuard is real, the framing was inflated. Confirmed: 70 orgs (government plus critical infrastructure) across 37 countries, disclosed February 5, 2026. The 155-country figure is reconnaissance, not compromise, and the
sys_read/sys_writehook detail is a class mechanic, not a verified ShadowGuard capability. - The mechanic is
d_reclen, not magic. Process and file hiding is a tracepoint onsys_exit_getdents64rewriting the previous dirent’s length withbpf_probe_write_userto skip the hidden entry. Understand that struct and the whole rootkit demystifies. bpf_probe_write_useris the tell. Legitimate observability reads memory constantly and writes to userspace essentially never. Alert on it directly.- Your LKM playbook is dead here.
lsmod,/proc/modules, kernel taint,rkhunter, and even Secure Boot are all blind to eBPF implants. Different trust boundary, different detections. - Load order wins. A rootkit can hide from
bpftoolby filtering its ownbpf()responses. The only reliable answers come from monitors installed before it (Falco, Tetragon) or from readingprog_idrout of a memory capture. Bake your telemetry into the golden image and never trust a post-hoc scan on a box you suspect is already owned.
Related Tutorials
- Access Tokens and Privileges: The Kernel’s Security Context
- System Calls and SSDT: How User Mode Reaches the Kernel
- HAL and Ntoskrnl: The Kernel Core Components
- User Mode vs Kernel Mode: Privilege Rings and the Boundary